Redis有五种数据结构,那么这5种数据结构底层分别是怎么实现的呢?《Redis设计与实现》这本书详细的介绍了Redis的数据结构,这里就提纲挈领的记录一下。
1 简单动态字符串SDS
这个也就是Redis的String类型,在Redis中所有的键都是String类型。值可以是String类型,也可以是其他类型。可以说String是Redis中使用的最频繁的类型了。
-
定义

实际上就是将c语言的char[]封装在结构体中。
-
空间分配策略
Redis会为SDS预分配空间,以减少字符串拼接时重新分配空间的时间损耗。
- 若对SDS修改后将小于1mb,则会为其额外分配一倍的空间。
- 若对SDS修改后将大于1mb,则额外分配1mb的空间。
2 链表
-
定义

最常见的双向链表节点的定义方式。

链表结构体,封装了首尾节点和长度。另外,使用函数指针将函数封装在结构体中,C厨是真的可怕。
3 字典
这里的字典实际上就是map,它用来存放键值对。Redis数据库本身就是通过字典来实现的。redis则字典通过hash表作为底层实现,可以将之理解为HashMap。
-
定义
redis实现hash表的方式与java实现hashmap类似,使用的是数组+链表的实现方式。数组作为hash表,链表解决hash冲突。
- hash表定义

- hash表节点定义:

- 一个完整的hash表结构:
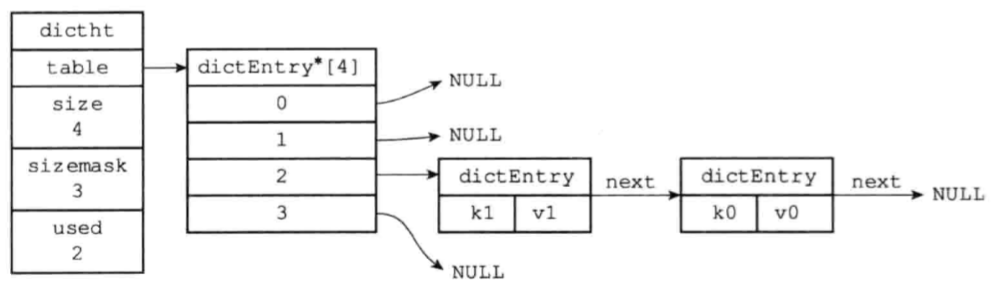
-
字典定义

注意到一个字典中有两个hash表ht[2],为什么呢?通常情况下使用的都是ht[0],在hash表扩容的时候才会使用ht[1]。
-
hash算法
hash算法与java的hashmap类似。
- 由一个hash函数计算得到一个hash值。
- 将hash值与size-1作&运算得到索引值(可见size同样应该是2^n)。
-
rehash
- 首先为h[1]分配空间,大小为第一个大于ht[0].used*2的2^n。(与hashmap稍有不同,hashmap是直接扩容为原来的两倍)
- 将所有节点rehash到ht[1]中。
- 释放ht[0],并将ht[0]指向ht[1]
-
渐进式rehash
如果hash表非常大的话,想要一次性rehash完毕可能会导致整个redis停顿,因此redis采用渐进式rehash方法。具体的做法是在为ht[1]分配完空间后并不马上开始rehash,而是在对ht[0]的增删改查时将对应元素rehash到ht[1]上,当ht[0]为空时rehash完毕。
4 跳表
跳表是一种有序的数据结构,其查询和插入性能与treemap相同,但实现比treemap简单,并且还支持范围批量查询。在Redis中跳表主要用在有序集合中。
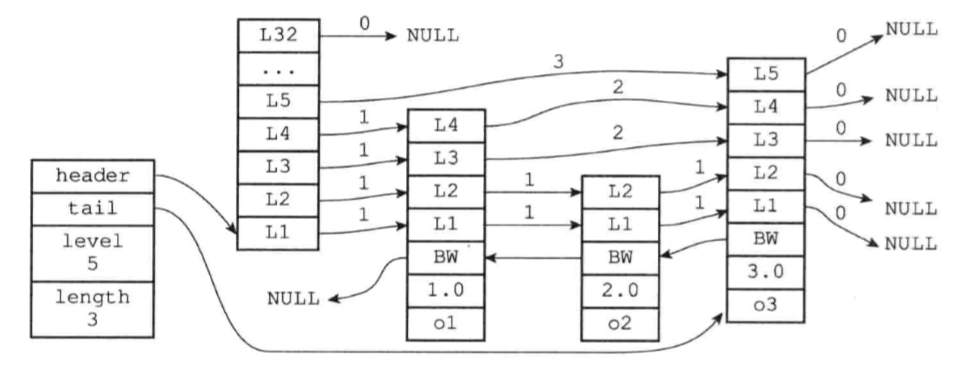
就是一个典型的跳表实现。
5 整数集合
整数集合就是存放整数的集合,它是Redis集合数据结构的底层实现之一,其中的元素按升序排列,并且不包含重复元素。
-
定义

有趣的是虽然我猜到它是基于数组来实现,但万万没想到它的数组单个元素大小是可变的。也就是说它可以从每个整数占8位变为每个整数占32位。
-
升级
升级就是它最奇特的部分。初始时每个整数占8位,当新加入一个超过8位的数时,比如16位,就要进行升级,升级过程如下:
- 首先按照每个整数占16位重新分配数组空间。
- 然后将所有数按照从大到小从后向前放置。
-
降级
抱歉,不支持降级。
6 压缩列表
压缩列表是list和hash表的底层实现之一。当list只包含少量的元素时,就会使用压缩列表实现。
-
定义
压缩列表实际上就是用一块连续内存实现的存储结构,其示意图如下所示:

- zlbytes:记录整个列表占用的字节数。
- zltail:记录尾节点的偏移量。
- zllen:节点数量。
- entryx:数据节点
- zlend:尾节点
-
节点构成

每个节点由三部分构成:
- previous_entry_length:上一个节点的长度,通过这个值,可以实现列表的从后向前遍历。
- encoding:记录数据类型及长度。
- content:具体保存的内容。
-
更新
对于这样紧凑的数据结构,不难想象插入、删除的复杂度都为O(n),实际上,由于“连锁更新”效应,最坏情况下的更新复杂度为O(n2)。至于连锁更新是什么,书上写的很清楚,就不赘述了。
7 对象
以上介绍了6种数据结构,但在实际使用Redis的过程中并不会直接使用它们,而是将它们再封装为5种类型的对象才能使用。也就是我们熟悉的字符串、列表、集合、有序集合、hash表。
-
定义

-
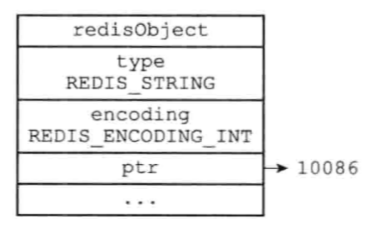
字符串
字符串对象可以使用SDS或long来实现,如果字符串保存的是一个整数,并且这个整数的范围在long之内,那么就将ptr转为long保存,如图:
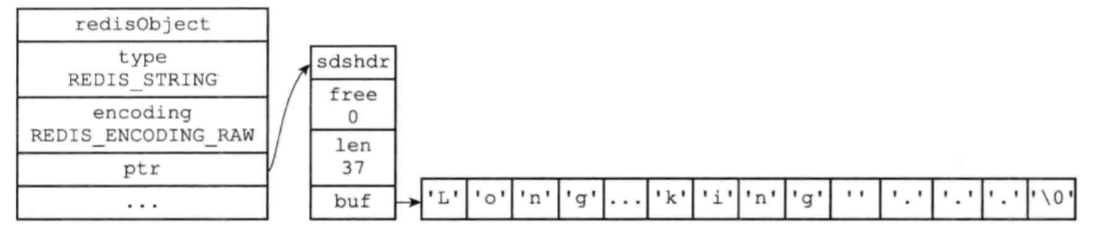
否则,ptr是一个指向SDS的指针:
-
列表
列表可以由ziplist或linkedlist实现,当满足以下两个条件时使用ziplist,否则使用linkedlist:
- 所有元素小于64字节。
- 元素数量小于512个。
-
hash对象
hash对象可以由ziplist或hashtable实现,当满足以下两个条件时使用ziplist:
- 所有键值对的键和值小于64字节。
- 元素数量少于512个。
如果是使用ziplist实现的hash对象,那么存储时并没有hash,而是直接按照插入顺序存储在ziplist中。
-
集合对象
集合对象可以由intset或hashtable实现,当满足以下条件时使用intset:
- 所有元素都是整数。
- 元素数量小于512个。
-
有序集合对象
有序集合对象可以使用ziplist或skiplist实现,当满足以下条件时使用ziplist:
- 元素都小于64字节。
- 元素数量小于128个。