今天在一边刷书一边在MySQL上练习时发现一个奇怪的问题,即使我查询使用的条件不是索引的前缀列也能用到此索引,这有点颠覆我的三观,后来百度了一下才知道这是MySQL 8.0以后才有的新特性。
1 问题描述
-
film_actor表
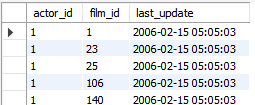
-
索引
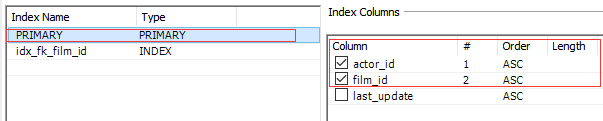
idx_fk_film_id索引已经被禁用。
-
查询语句
EXPLAIN SELECT film_id FROM film_actor WHERE film_id=1;按照以往的认识,film_actor不是索引的前缀列,所以这个语句应该是用不了PRIMARY索引的,但是看一下结果:

WTF?惊呆了好么,显示竟然用到了PRIMARY索引。这是怎么回事呢?
2 解释
看一下Extra中的内容。
Using where:表示在查找使用索引的情况下,需要回表查询所需数据。
Using index for skip scan:表示使用索引跳跃扫描。
关键就在于这个索引跳跃扫描,它表示什么意思呢,百度一下。它表示:
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),它使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该 索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样(实际的执行过程并非如此),这也是索引跳跃式扫描中”跳跃”(SKIP)一词的含义。
说通俗一点,可以理解为优化器做了以下工作:
-
首先,将actor_id所有的可能值枚举出来。
-
然后将查询语句改成:
SELECT film_id FROM film_actor WHERE actor_id=1 AND film_id=1 UNION ALL SELECT film_id FROM film_actor WHERE actor_id=2 AND film_id=1 UNION ALL SELECT film_id FROM film_actor WHERE actor_id=3 AND film_id=1 ... ... ...这个语句是可以使用PRIMARY索引的。
这样做在索引前缀列的枚举值较少时,可以避免全表扫描,提高了查询速度,但是如果枚举值太多的话,先进行一次枚举和改写SQL语句也要消耗一定的性能,那么还不如在非前缀列上重新建立一个索引。因此,优化器也会根据枚举值的数量来决定是否使用此特性。
这个特性在Oracle数据库中早就有了,但是在MySQL 8.0之后才加入。